2026/06/03
Claude Code / Codex のコアの仕組みを理解する
Tool-Use-Agent-Loop
- AI-Agent
- Coding-Agent
- Claude-Code
- Codex
- LLM
はじめに
ここ1, 2年ほど、「AI Agent」という単語がバズワードになっている。
このワードが話題になり始めた2年ほど前(まだ2年!)は、Chatモデルが出力したテキストを次のChatモデルへの入力とする、すなわち直列にLLMを繋ぎ合わせてユーザーの要求を達成する構成が主流であった。いわゆるAIワークフローというやつである。このAIワークフローはChatモデルが達成できるタスクの幅を大きく広げたが、一方で、決められた手順に従って決められた範囲内のタスクしか遂行できない、Chatモデル間のInput/Output間で不整合が起きやすい、などの問題があった。
その後、2025年2月にAnthropicがClaude Codeを発表、少し遅れて同4月にOpenAIがCodex CLIを発表した。これらは2026年5月時点においてもコーディングエージェント界のトップに君臨するプロダクトである。特にCodexはオープンソースとしてソースコードが公開されており、その動作原理が従来のワークフロー型ではなく、Tool Useを主体としたAgent Loopであることが認知されている。(非公開ではあるものの、先行のClaude Codeも同様のAgent Loopを主体としていると考えられる。)
また、OpenAIは2026年1月〜3月にかけて、以下に示す2本のAgent Loopに関する興味深いブログをポストし、Codexの動作原理の詳細をドキュメントとして公開している。
- Unrolling the Codex agent loop
- From model to agent: Equipping the Responses API with a computer environment
この「Tool Useを主体としたAgent Loop」は、決して最新のハイエンドなコーディングエージェントだけのものではなく、例えば自前でAIエージェントを作成する際にもベースとすべき有用な基本構成である。
そこで本記事では、上記2本のブログ記事を参考に、このAgent Loopの仕組みについて整理する。
「Tool Useを主体としたAgent Loop」とは
最新のAIエージェントの動作原理は驚くほどシンプルである。
OpenAIのブログにある以下の図が最も理解しやすいが、文章として書き起こすと、 「LLMモデルはTool Useのリクエストか、テキストを返す。Tool Useリクエストが返された場合は対象のツールを使用してその結果を会話履歴に加えて再度LLMモデルに投げるLoopを継続する。テキストが返された場合は最終回答としてそれをユーザーに出力する。」 となる。
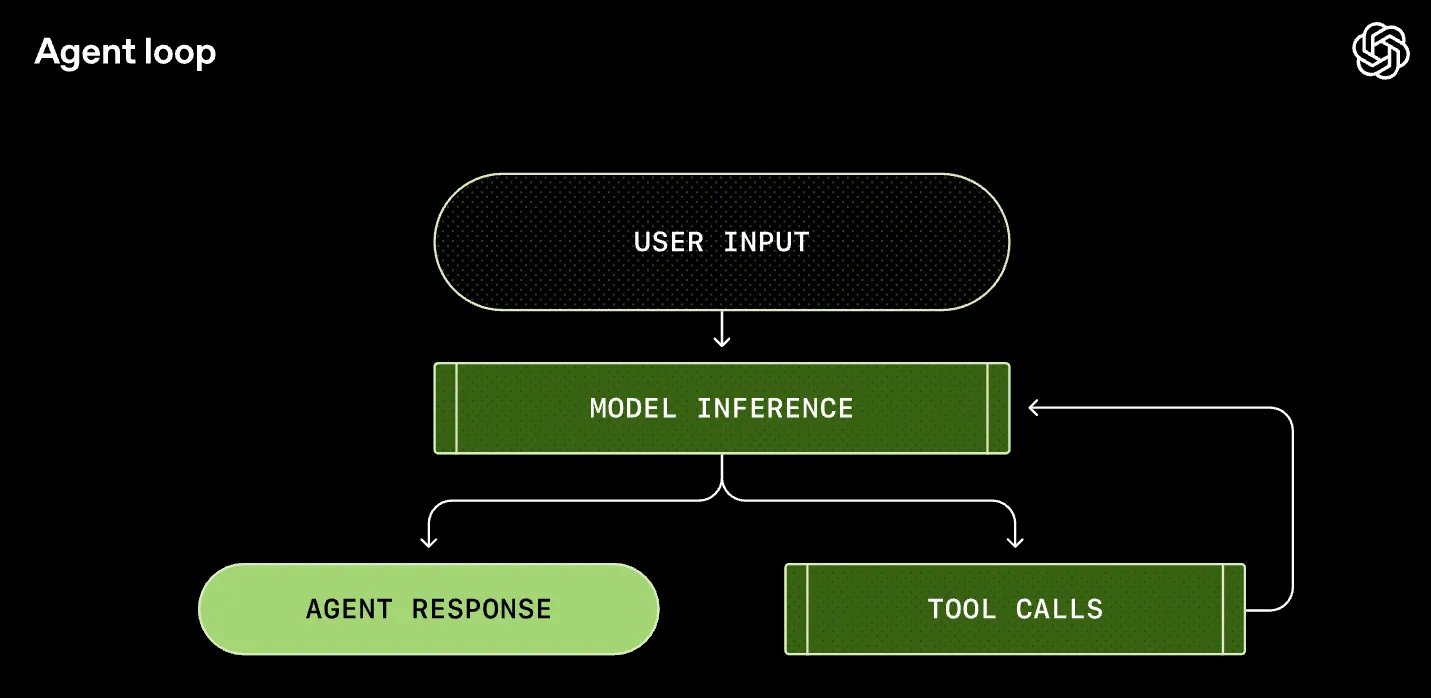
図 Tool Useを主体としたAgent Loop (https://openai.com/index/unrolling-the-codex-agent-loop/)
例えばPythonでは、以下のようなシンプルなforループでこのAgentの挙動を表現することができる。
messages = [{"role": "user", "content": task}]
for _ in range(max_iterations):
response = call_llm(messages, tools=tools)
if response.function_call is None:
answer = response.text
break
tool_result = call_tool(response.function_call)
messages.append(response.function_call)
messages.append(tool_result)ここではLLMへの入力形式やresponseの構造などを簡略化して記載しており、実際とは異なることに注意する。
Toolについて
LLMが使用をリクエストするToolは、代表的なものとして以下が挙げられる。
- Shell Tool
- File Read Tool
- File Write Tool
- Web Search Tool
- Web Fetch Tool
これらのToolの実行結果はそれぞれ独立に定義されたスクリプトによってもたらされる。すなわち、ほとんどのToolの実行結果はLLMの出力のような確率論的なものではなく、決定論的である。
例えばShell Toolの場合、以下のようなシンプルなスクリプトで定義することができる。
import subprocess
def shell_tool(command: str) -> dict:
return run_shell(command)
def run_shell(command: str) -> dict:
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
)
return {
"exit_code": result.returncode,
"stdout": result.stdout,
"stderr": result.stderr,
}具体的には、LLMから返ってきたShell Toolの使用リクエストJSONをパースし、コマンド部分を取り出して shell_tool 関数を呼び出し、関数からの返り値をパースしてコマンドの実行結果を取得し、それを会話履歴の一番後ろに追加して再度LLMに投げる、という処理が走ることになる。
なお、OpenAIの2つ目の記事 From model to agent: Equipping the Responses API with a computer environment では、Shell Toolを有効に使うためにはLLMモデルがShellコマンドを適切に提案できるように訓練されている必要があることが示唆されている。OpenAIのモデルにおいてはGPT-5.2以降のものがこれに対応している。
Claude CodeやCodexにおける「Skills」という仕組みは、このToolをユーザーが自由に定義できる形に拡張したものと捉えることができる。独自実装においては、コードのみで実現できる仕組みであればToolとして定義し、逆に自然言語(+コード)で定義すべき仕組みであればSkillsに乗せるといった使い分けになると思われる。
Sandbox環境について
Coding Agentには以下のようなセキュリティリスクが存在する。
- Homeディレクトリ上の設定ファイルなど、重要なファイルの内容を勝手に書き換えてしまう
- APIキーなどのシークレット情報を漏洩させてしまう
- 悪意あるWebサイトに不用意にアクセスしてしまう
こういったリスクを極力避けるために、AgentによるTool実行はSandbox環境内で実行することが好ましい。
Codexでは、以下のようにOSに合わせてSandbox機構を使い分けている。
| OS | Sandbox機構 |
|---|---|
| MacOS | Seatbelt |
| Linux | bubblewrap + seccomp |
| Windows | Restricted Token + ACL / Capability SID |
独自AgentでSandbox環境を使用したい場合は、Dockerがシンプルで使い勝手が良いと思われる。
少なくともShell Toolなどの比較的リスクの高いToolは、以下のように docker コマンドの中に入れて実行することが好ましい。
import subprocess
from pathlib import Path
def shell_tool(command: str, workspace_dir: Path) -> dict:
result = subprocess.run(
[
"docker",
"run",
"--rm",
"--network",
"none",
"--workdir",
"/workspace",
"--volume",
f"{workspace_dir.resolve()}:/workspace",
"python:3.12-slim",
"sh",
"-lc",
command,
],
capture_output=True,
text=True,
)
return {
"exit_code": result.returncode,
"stdout": result.stdout,
"stderr": result.stderr,
}この例では、ホスト側の作業ディレクトリを /workspace としてコンテナにマウントし、その中でコマンドを実行している。また、--network none を付けることで、コンテナ内からのネットワークアクセスを禁止している。
ただし、実際にはネットワークアクセスを完全に禁止するのではなく、必要なドメインに絞ってアクセスを許可したいケースが多い。Codexではネットワークアクセス用のSandbox環境として、ホスト型コンテナにサイドカー型のエグレスプロキシを使用する方式を取っている。すなわち、メインのコンテナは直接インターネットに出ることはできず、サイドの補助的なコンテナのプロキシを通じて許可リストに含まれるドメインにのみアクセスできるようになっている。
Prompt Builderについて
現在のCoding Agentでは、ユーザーの入力がそのままLLMモデルに渡されるわけではない。実際には、ユーザーの入力以外に、CLAUDE.md (AGENTS.md) の内容、Toolの一覧と説明、Permissionの設定などを含んだPromptを構築し、それがLLMモデルに渡されることになる。
Codexでは、先頭から順に以下のように情報を並べて全体のPromptを構築している。
<サーバー側で定義される情報>
- Identityの定義(あなたはChatGPTで…)
- Toolの定義
- モデルに関連づけられたInstruction
<クライアント側で定義される情報>
- Permissionの指示
config.tomlで定義したdeveloper_instructionsAGENTS.md- ローカル環境に関する説明
- ユーザー入力
このように、一度に送信されるPromptの規模は、ユーザーが想像するよりもはるかに大きい。(これが CLAUDE.md を50〜100行程度に収めておいたほうが良い理由である。)
また、CodexではAgent Loop中に、 前回までのインプットを完全な形でそのまま次のインプットのプレフィックスとして使用 している。これは、過去のインプットに完全に一致する部分に関してはKV cacheの仕組みが働き、計算速度やコスト効率が大幅に向上するためである。なお、 インプットの先頭から完全一致 させる必要がある点に注意する。
独自実装においても、特にLLMモデルにプロバイダのAPIを使用する場合には、上記のようにCache Hitを意識してPromptを構築することが好ましい。
Coding Agentのコア構成まとめ
以上をまとめると、Claude CodeやCodexなどのハイエンドなCoding Agentは、以下のようなコア構造を持っている。
- LLMから最終出力のテキストが返されるまでTool Useを繰り返すAgent Loop
- Toolを使用するためのSandbox環境
- 必要な情報を適切な順序で組み立ててPromptを構成するPrompt Builder
全体構成を図示すると以下のようになる。
flowchart TB
PB["Prompt Builder<br/>Instructions / Tools / Permissions / User Input"]
Prompt["Prompt / Conversation History"]
LLM["LLM"]
Response{"LLM Response"}
Final["Final Answer"]
Append["Append Tool Result<br/>to the end of Prompt"]
PB -->|"Build initial prompt"| Prompt
Prompt -->|"Send to model"| LLM
LLM --> Response
Response -->|"Text"| Final
Response -->|"Tool Use Request"| Runner
subgraph Sandbox["Sandbox"]
Runner["Tool Runner"]
Tool["Shell / File / Web Tool"]
Result["Tool Result"]
Runner --> Tool
Tool --> Result
end
Result --> Append
Append --> Prompt
図 Coding Agentのコア構造
ここで、上図では全てのToolがSandbox環境内で実行されているように見えるが、これは表現を簡略化するためであり、Codexにおいても一部のToolはローカル実行されていることに留意する。
PythonでCoding Agentを自作してみた
というわけで、主に学習用途としてCoding Agentのコア機能部分をシンプル化して(僕が理解しやすい)Pythonで再構築し、「Gear Code」として公開してみた。
https://github.com/TsuyoshiFujii-0915/gear-code
LLMモデルは、OpenAIのResponses APIもしくはLM StudioのResponses API互換エンドポイントを経由してアクセスすることを想定している。
Toolとしては最小構成として以下の8種類を定義している。
- Shell Tool: シェルコマンドを実行する
- File Read Tool: ファイルの内容を読み取る
- File Write Tool: ファイルに書き込みを行う
- Apply Patch Tool: Unified Diffパッチを適用する
- Glob Tool: ファイルとディレクトリを
globパターンで検索する - Grep Tool: テキストファイルを正規表現で検索する
- Web Search Tool: Web検索を実行する(Tavily Search APIを使用)
- Web Fetch Tool: URLの本文を取得する(Tavily Extract APIを使用)
uv run gear でTUIを起動してチャットから指示が出せる。
ローカルモデル(Qwen3.5:9B)であっても、この仕組みだけで結構ちゃんと動く。プロジェクトの中身を見て説明し、それをMarkdownとして書き出すこともできるし、簡単なHTMLのWebページを作成することもできる。(それ以上のタスクはまだ試せていないが、それらを実行できるポテンシャルは十分にあるように感じる。)
LLMが使用できるToolは config.toml で指定することができる。また、ユーザーのニーズに合わせて独自でToolを定義して拡張することもできる。
今後もこのGear Codeを拡張していくつもりではあるが、Gear Codeの開発をGear Code自身にやらせたら面白そうだな〜とか一人で勝手に考えたりしている。
さいごに
最後にこんなこと言うのはアレだが、ハイエンドなCoding Agentを使って有用なプロダクトを生み出したいだけであれば、正直絶対にClaude CodeかCodexを使うべきであると筆者は考えている。
が、実際にはClaude CodeやCodexを自由に使える環境にある人ばかりではない。また、場合によっては独自の権限とツールのみをLLMに与えて最小構成でエージェントを組みたいケースは少なからず存在するだろう。OpenAIやAnthropicなどのメガプラットフォーマーが提供するサービスはより一般的な用途をターゲットとしており、上記のようなニーズにまで対応することは難しい。
したがって、現在のハイエンドなCoding (もしくはAI) Agentの仕組みを理解した上で自分で構築できるようにしておくことには一定の意味があると考える。
というわけでこのまとめが誰かの役に立つことを願いつつ、Gear Codeも今後拡張していきたいと思っているのでぜひcloneして遊んでみていただけると嬉しい。