2026/03/28
Responses APIにコンピュータ環境を装備する
OpenAIのブログポスト「From model to agent: Equipping the Responses API with a computer environment」について
- AI-Agent
- LLM
3/13にOpenAIが公開した記事「From model to agent: Equipping the Responses API with a computer environment」が面白いと感じたので、記事の中で重要な部分を抜粋してまとめる。
翻訳も兼ねて記事を書いていたのだが、執筆中に英文記事から遅れて日本語の記事が公開されて萎えた。 本文の内容については元記事を参照いただき、本記事では筆者が付け加えた注釈部分をメインに読んでいただきたい。
はじめに
AIエージェントを構築しようとすると、いくつかの実践的な問題が浮上する。それらは、中間ファイルをどこに置くか、大きなテーブルをプロンプトに貼り付けることをどう避けるか、セキュリティ上の安全を担保しつつワークフローにネットワークアクセスをどう付与するか、そして独自のワークフローシステムを構築することなくタイムアウトやリトライをどう処理するか、などである。
OpenAIのResponses APIは、シェルツールとホスト型コンテナワークスペースとを組み合わせることで、開発者に独自の実行環境を構築させることなくこれらの問題に対処できるよう設計されている。
この記事では、エージェント向けのコンピュータ環境をどのように構築したかを解説する。
シェルツール
優れたエージェントワークフローは緊密な実行ループから始まる。モデルがファイルの読み取りやAPIなどのデータ取得などのアクションを提案し、プラットフォームがそれを実行し、その結果が次のステップの入力に加えられる。シェルツールはこのループを動かす最もシンプルな方法である。
シェルツールはコマンドラインを通じてコンピュータと対話し、テキスト検索やAPIリクエストの送信といった幅広いタスクを実行する。Unixツール群の上に構築されており、grep、curl、awk などのユーティリティをすぐに使用することができる。また、Pythonのみを実行する既存のコードインタープリターと比較して、シェルツールはGoやJavaプログラムの実行やNode.jsサーバーの起動など、はるかに幅広いユースケースに対応できる。この柔軟性により、モデルは複雑なエージェンティックタスクを遂行できるようになる。
ただし、モデルはあくまでツール呼び出しを提案しているだけであり、モデル自身がその呼び出しを実行することはできない。
エージェントループのオーケストレーション
シェルコマンドの実行を含むエージェントループをオーケストレーションする役割を、Responses APIが担う。
Responses APIがプロンプトを受信すると、ユーザープロンプト、会話履歴、ツール指示などを連結してモデルコンテキストを組み立てる。このコンテキストをもとにモデルがシェル実行を選択した場合、1つ以上のシェルコマンドをResponses APIサービスに返す。APIサービスはそれらのコマンドをコンテナランタイムに転送し、シェル出力をストリーミングで返し、次のリクエストのコンテキストとしてモデルに入力する。モデルはその結果を確認し、フォローアップコマンドを再提案するか、最終的な回答を生成できる。Responses APIは、モデルが追加のシェルコマンドなしで完了(最終的な回答)を返すまでこのループを繰り返す。
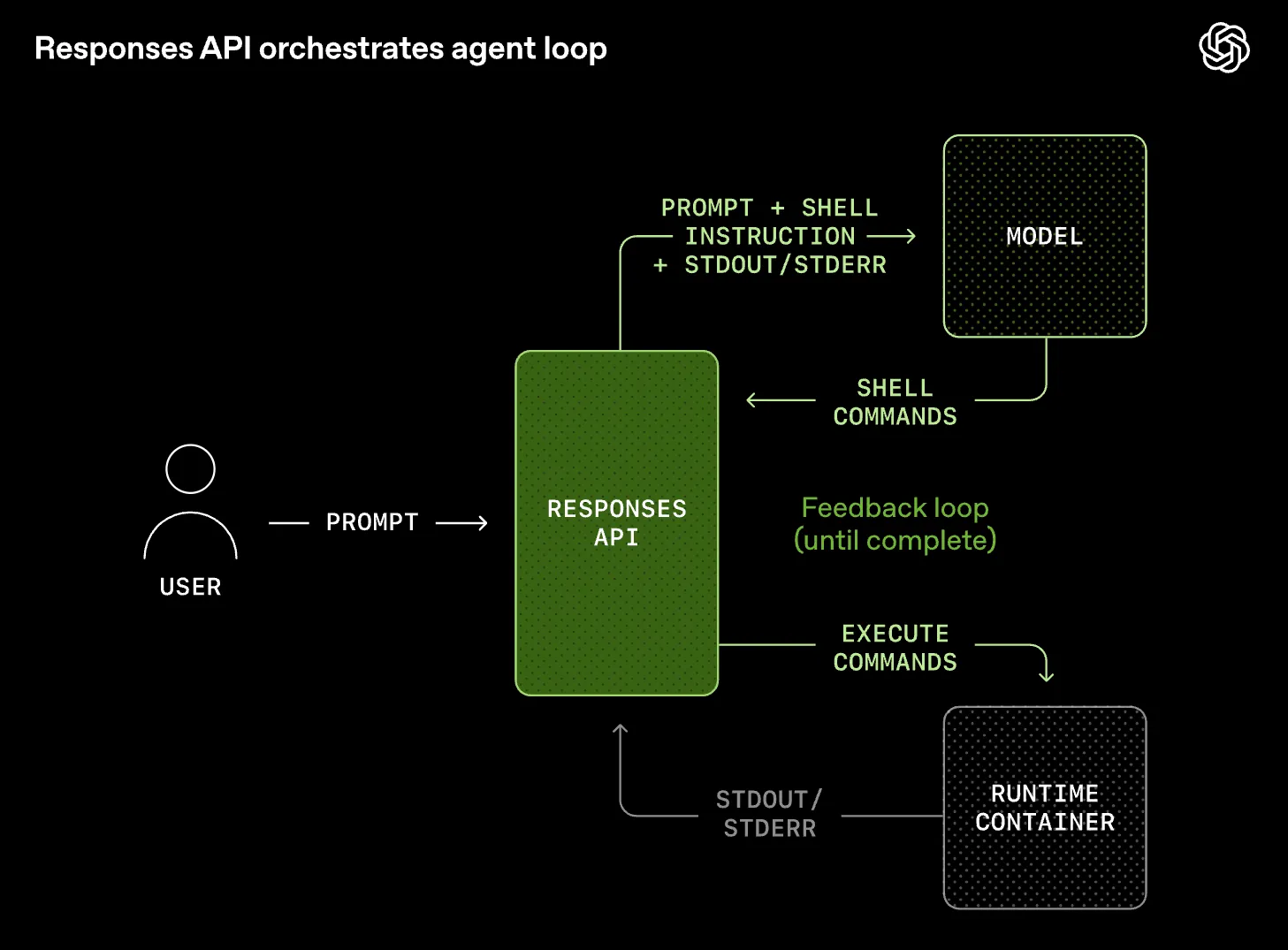
図 エージェントループのオーケストレーション (記事より抜粋)
なお、シェル実行が機能するには、プロンプトがシェルツールの使用に言及し、選択されたモデルがシェルコマンドを提案するよう訓練されている必要がある: GPT-5.2以降のモデルがこれに対応している。
OpenAIが2026年1月に発表したOpen Responsesには、このシェルツールをコンテナランタイムで実行する機能は含まれていない点に注意が必要である。Open Responsesは外部ホスト型(クライアント側の関数やMCPサーバーなど)と内部ホスト型(プロバイダ側で実行されるプロセス)におけるツール呼び出しのプロトコルを標準化するものであり、シェルツールなどの実行環境の提供如何は各プロバイダの責任範囲となっている。したがって、LM Studioなどのローカル推論サーバーでResponses API互換を使用してシェルツールを含むエージェントループを実現したい場合は、サンドボックスを立ち上げて
docker execでシェルコマンドを実行するといった仕組みを自前実装する必要がある。
「モデルがシェルツールを使用できるよう訓練されている必要がある」という言及は注目に値する。これは主に (1) シェルを使うべき場面を判断する (2) 適切なコマンドを選択する (3) アウトプットやエラー文を見て適切に次の一手を選択する、といった能力をモデルが獲得している必要があることを意味する。すなわち、ローカルLLMなどの非OpenAIモデルでは、この能力が備わっていないためにシェルツールの使用が安定しないといった事象が起きうることを示唆している。
モデルは一つのステップで複数のシェルコマンドを提案することができ、Responses APIは別々のコンテナセッションを使ってそれらを同時並行的に実行できる。すなわち、エージェントループはファイル検索、データ取得、中間結果の検証などの作業を並列化できる。
コンパクション
エージェントループが持つ潜在的な問題の一つは、タスクが長時間実行されうることである。長時間のタスクはコンテキストウィンドウを埋め尽くす。この問題に対処するため、Responses APIにはコンパクション機能が備えられている。これはモデルの振る舞いと訓練方法に整合するよう設計されている。
最新のモデルは、以前の会話状態を分析し、暗号化されたトークン効率の高い表現で過去の重要な状態を保持するコンパクション結果を生成するよう訓練されている。コンパクション後のコンテキストウィンドウは、このコンパクション結果と、以前のウィンドウの高価値部分で構成される。このメカニズムによって、Codexは長時間のコーディングタスクや反復的なツール実行を品質を低下させることなく実行している。
コンパクションにおいてもモデルの事後学習が鍵になっていることが示唆されている。「暗号化されたトークン効率の高い表現」でコンパクションを行っている事実は、これがただの要約ではないことを意味している。Codexのコンパクション能力が競合に比べて高いと言われるのは、この独自方式が理由であると考えられる。
コンテナコンテキスト
コンテナはコマンドを実行する場所であるだけでなく、モデルの作業コンテキストでもある。コンテナ内でモデルはファイルを読み取り、データベースにクエリを実行し、ネットワークポリシーの制御下で外部システムにアクセスできる。
ファイルシステム
コンテナコンテキストの最初の要素は、リソースのアップロード、整理、管理のためのファイルシステムである。OpenAIはコンテナおよびファイルのAPIを構築し、モデルが利用可能なデータのマップを持ち、広範でノイズの多いスキャンを行う代わりに的を絞ったファイル操作を選択できるようにした。
よくあるアンチパターンは、全ての入力をプロンプトコンテキストに直接詰め込むことである。より良いパターンは、コンテナのファイルシステムにリソースをステージングし、「何を開き、パースし、変換するか」をモデルにシェルコマンドで判断させることである。
すなわち、ファイルの中身全てをプロンプトに載せるのではなく、ファイルシステム+「何がどこにあるか」のメタ情報だけをLLMにプロンプトとして渡し、モデルがシェルツールを用いて自分で該当情報を取得する方式が現状のベストプラクティスである。
ここで言及されているAPIとは、Containers API および Container Files API を指し、これらは一般の開発者が自由に利用できるパブリックなAPIである。
データベース
コンテナコンテキストの2番目の要素はデータベースである。多くの場合、開発者には構造化データをSQLiteなどのデータベースに格納し、クエリすることを推奨する。スプレッドシート全体をプロンプトにコピーする代わりに、テーブルの説明(どんなカラムがあり、何を意味するか)をモデルに与え、必要な行をモデル自身に取得させることができる。
例えば、「今四半期に売上が減少した製品はどれか?」と尋ねた場合、モデルはスプレッドシート全体をスキャンする代わりに、関連する行だけをクエリできる。これはより高速で、より安価で、より大規模なデータセットにスケーラブルである。
ネットワークアクセス
コンテナコンテキストの3番目の要素はネットワークアクセスである。これはエージェントワークロードにおける不可欠な部分である。エージェントのワークフローでは、ライブデータの取得、外部APIの呼び出し、パッケージのインストールなどが必要になることがある。一方で、コンテナに無制限のインターネットアクセスを与えることにはリスクがある。
そこで、OpenAIはこのリスクに対処するため、ホスト型コンテナにサイドカー型のエグレスプロキシを使用するよう構築した。すべての外部ネットワークリクエストは集中化されたポリシーレイヤーを通過し、許可リストとアクセス制御を強制しつつ、トラフィックを観測可能な状態に保つ。認証情報については、エグレス時にドメインスコープのシークレットインジェクションを使用する。モデルとコンテナはプレースホルダーのみを参照し、生のシークレット値はモデルから見えるコンテキストの外に留まり、承認された宛先に対してのみ適用される。
要するに、OpenAIが構築したネットワークアクセスの仕組みにおいて押さえておくべきキーワードは以下の2点である。
- サイドカー型のエグレスプロキシ: メインのコンテナは直接インターネットに出られず、サイドの補助的なコンテナのプロキシを通じて許可リストに含まれるドメインにのみアクセスできる。
- ドメインスコープのシークレットインジェクション: モデルとコンテナはシークレットの本物の値を一切知らず、プレースホルダー(
$OPENAI_API_KEYなど)のみを情報として持つ。モデルが発行したリクエストがエグレスプロキシを通過する際に、宛先が許可リストにあることを確認した上で、 プロキシがリクエストのプレースホルダーを本物の値に変換 する。この仕組みによって、別ドメインへのシークレットの誤送信やプロンプトインジェクションによってモデルからシークレットが流出するリスクを抑えている。
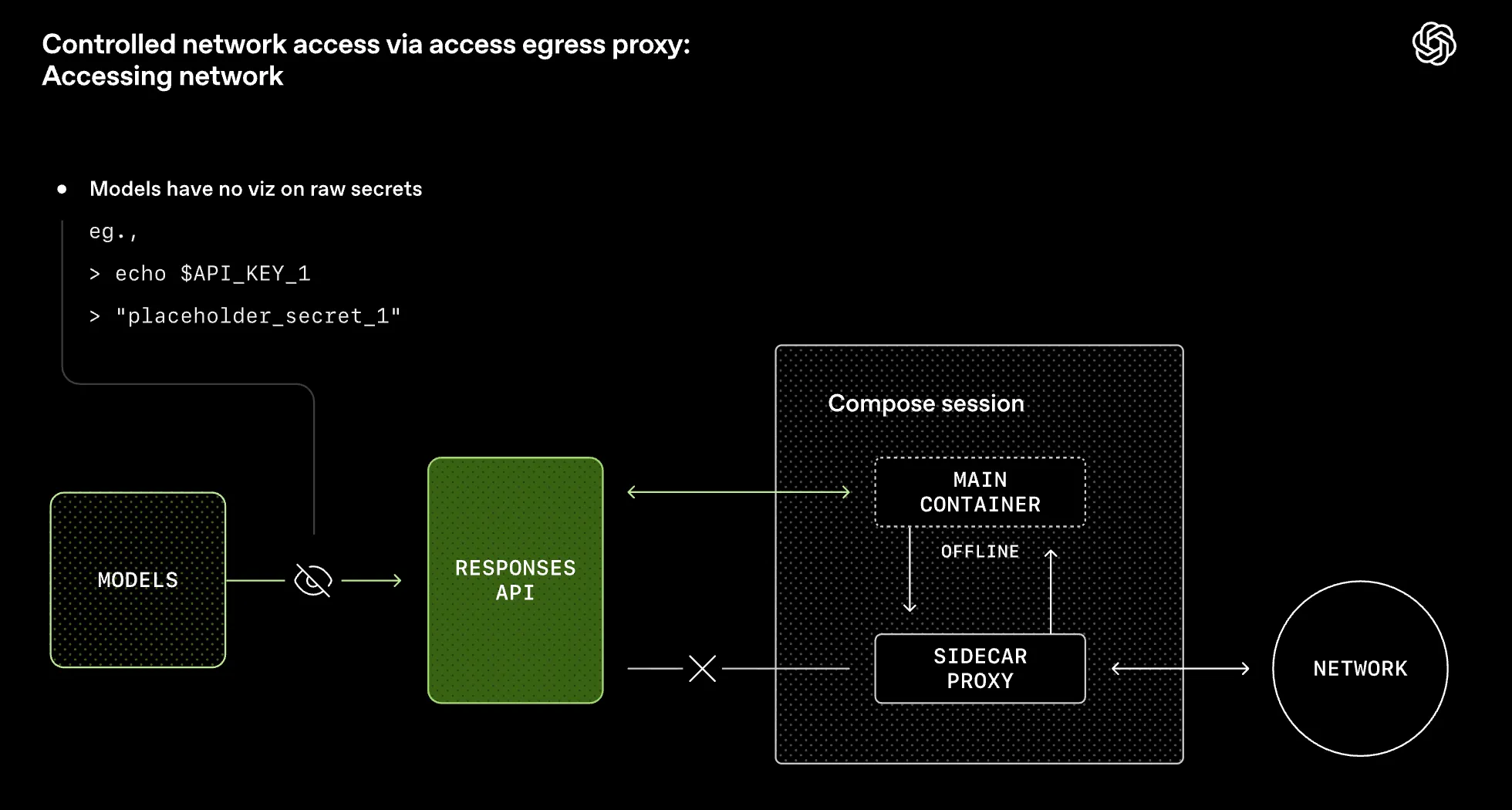
図 エグレスプロキシによる制御されたネットワークアクセス (記事より抜粋)
Agent Skills
シェルコマンドは強力だが、多くのタスクは同じ複数ステップのパターンを繰り返す。エージェントは各実行時にワークフローを再発見しなければならず、これは結果の不一致と実行の無駄につながる。Agent Skillsはこれらのパターンを再利用可能で組み合わせ可能なビルディングブロックにパッケージ化する。具体的には、Skillはフォルダバンドルであり、メタデータと手順を含む SKILL.md と、APIスペックやUIアセットなどのサポートリソースで構成される。
この構造は、先に説明したランタイムアーキテクチャに自然にマッピングされる。コンテナが永続的なファイルと実行コンテキストを提供し、シェルツールが実行インターフェースを提供する。これらが揃うことで、モデルは必要に応じてシェルコマンド(ls、cat など)でSkillファイルを発見し、指示を解釈し、同じエージェントループ内でSkillスクリプトを実行できる。
OpenAIプラットフォーム上でSkillを管理するためのAPIが提供されている。開発者はSkillフォルダをバージョン管理されたバンドルとしてアップロード・保存し、後からSkill IDで取得できる。プロンプトをモデルに送信する前に、Responses APIはスキルを読み込み、モデルコンテキストに含める。このシーケンスは決定的(確定的)である:
- スキルのメタデータ(名前と説明を含む)を取得する。
- スキルバンドルを取得し、コンテナにコピーして展開する。
- スキルのメタデータとコンテナパスでモデルコンテキストを更新する。
スキルが関連するかどうかを判断する際、モデルはその指示を段階的に探索し、コンテナ内のシェルコマンドを通じてスクリプトを実行する。
さいごに
独自のエージェントを構築する際に押さえておくべき要素が数多く含まれる記事であり、とても参考になった。